Some months ago I started working on Akraino Edge Stack https://wiki.akraino.org. Akraino is an open source software stack that improves the state of edge cloud infrastructure for carrier, provider and IoT networks. It belongs to LF edge org https://www.lfedge.org, and is composed of more than 11 blueprint families, to support a variety of edge use cases (5G, AI/ML, Video Processing…)
But the first question to answer would be: Why Edge computing ? The demand for real-time processing capabilities raises a need to place computing at the edge instead of relying on centralized processing. It brings processing and storage capabilities closer to the user endpoint, using the cloud. It reduces cost of ownership, enables faster processing, and meets specific data privacy rules.
A typical service provider will have thousands of Edge sites that are deployed at a cell tower, central offices… so end-to-end edge automation and zero-touch provisioning are required to minimize OPEX and meet requirements for agility. For resiliency, the deployment follows a hierarchy of deployments: collection of central sites, regional sites and edge sites. These deployment are achieved using a conceptual blueprints model. Much as a contractor can adapt a base house blueprint to fit the needs of a particular family, Akraino base blueprints target a specific application category but can be customized for a specific deployment. Formally, a blueprint is a declarative configuration of an entire stack addressed for specific use cases (5G, AI/ML…), using a reference architecture developed by the community.

A declarative configuration is used to define all components in the ref architecture: hardware, software, tools, method of deployment, etc.. KNI (Kubernetes Native Infrastructure) is a family of blueprints inside Akraino, that leverages best-practices and tools of Kubernetes to declare edge stacks. And this is the project to which my colleagues and I contribute!
If you are interested, please, come and join!

Kubernetes Native Infrastructure
We have decided to use Kubernetes, and more specifically, Red Hat’s distribution of K8s called Openshift, because a good number of reasons. First of all, our goal was to be able to define in a declarative way an entire edge stack, from the underlying infrastructure up to the applications running on top, going through how the actual cluster looks like in terms of features, versions, etc.
With this, the goal is to leverage the rich tooling and best-practices of Kubernetes community and ecosystem. Kubernetes has embedded in its DNA the declarative way of managing applications, and we believe that the infrastructure can be managed following the same approach. By using operators and controllers, we create loops that will compare the desired state represented in the declarative configuration, and the reality, and act for reconciliation. Furthermore, Akraino KNI Edge Stack allows for a hybrid type of deployments by supporting Virtual Machines. The entire stack leverages awesome projects such OKD, CNI, Rook, Prometheus, Kubevirt, etc.

We initially started defining two blueprints:
- Provider Access Edge
- Industrial Edge
Currently, we are focused in the first blueprint by including different target platforms (Libvirt, AWS, baremetal) and enabling specific features for Telco/5G/vRAN type of workloads such as SRIOV support, PTP, Real-Time Kernel, etc.

Since we wanted to leverage the awesome user experience of deploying OpenShift, we decided not to create a wrapper out of it, but to create a helper tool that will allow the users of the project and the edge network operators, to pick a blueprint model (like blueprint PAE) and be able to customize it easily adding workloads on top, or enabling new features. That helper tool is called knictl.
The way that a KNI blueprint is structured starts by a base blueprint, with basic configuration (Kubernetes cluster). On top of this, we apply what we call a profile, which will define the actual platform where the cluster is going to be deployed (Libvirt, AWS, baremetal and more to come…).
Finally, we customize if needed by creating the actual site folder, that will inherit the configuration from the picked profile plus the base configuration. This rendered mix is done underneath with Kustomize.

What’s coming?
As I mentioned before, the team is very focused on the “Provider Access Edge” blueprint. The typical type of workloads in these types of deployments, have dataplane and performance instensive requirements. That’s why, we are enabling very specific features for these telco applications such:
- SRIOV Network Operator
- Precision Time Protocol
- Real Time Kernel
- CPU pinning
- Hugepages support
- Baremetal automation
- Etc.
So as you can understand, all these features are specific to the platform, but since Akraino is about defining the entire stack from top to bottom, we are working with Eurecom in order to enable the deployment of OpenAirInterface. OAI is an open source project that provides an open implementation of a telco core network (EPC), access network (vRAN) and user equipment. Enabling OAI in our PAE blueprint, will show the entire stack of one of the most promising use-cases of the industry.
Hands on!
I’ve recorded a couple of videos to show how a deployment of the same blueprint, on two different footprints (Libvirt and AWS) looks like. The user workflow can be described with the following steps:
- knictl: so far there is no available binary to download, but you can git clone the project kni-installer and do a
make buildinside of the folder. - Create site: build the desired stack in a folder using Kustomize files. Inside the blueprint-pae, there are examples of sites, that point to certain profiles.
- Fetch requirements: execute
knictl fetch_requirements file:///path/to/mySite. knictl supports sites not only in a folder, but in a git repo. - Prepare manifests: execute
knictl prepare_manifests mysite. This step will render all the files (base, profile and site) and will get K8s native manifests to be deployed by OpenShift Installer. - Deploy cluster: the output of the previous step will show what’s the exact command to execute, but basically it’s something like
openshift-install create cluster --dir /path/to/mySite. - Apply Workloads: this last step is meant to perform kind of Day 2 operations. It will read the manifests located in 02_cluster_addons and 03_services inside your site’s definition, use kustomize on them and apply to the cluster.
Following this workflow will allow the network edge operators to have the same user experience, no matter what type of site is being deployed, in which footprint or what applications will be running on top.
Libvirt deployment
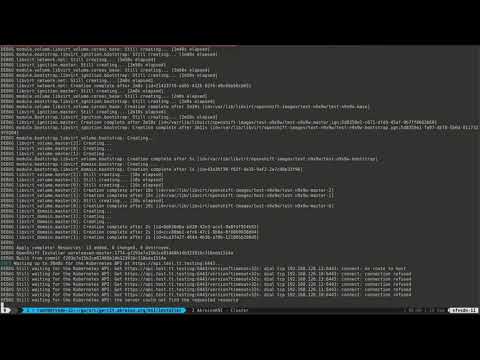
AWS deployment
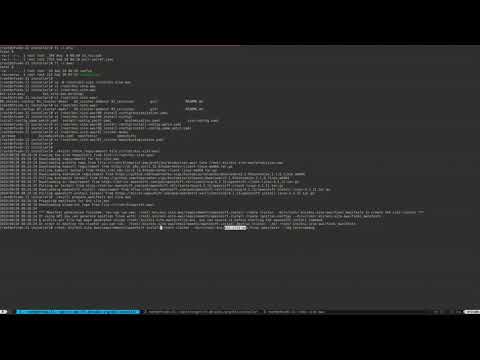
If you have any question about the playbook, or any other subject, contact me via twitter, email, etc